两个中文句子相似性比较
前言:这是2018年招行FinTech管培生的复赛第二题,计算两个句子相似性。第一次接触机器学习,做得很简单,mark一下。
1. 问题描述
题目:查找最相似新闻TOP 20;
给定数据:
test_data.csv:测试数据,每行包括id和title,共50条。
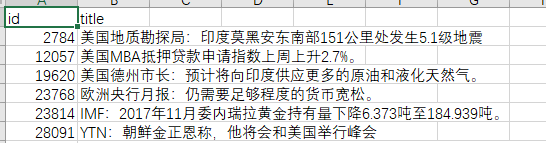
train_data.csv:训练数据,和测试数据格式相同,共485686条。

目标:为测试数据中的每条数据找到对应的最相似的20条(去除本身)。
评价标准:
官方给定正确答案,根据以下算法计算提交答案的分值:
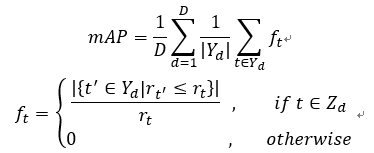

示例:
对新闻A选定top10相似新闻,如果正确答案的{a,b,c,d,e,f,g},第一人提交答案是:{a,g,o,f,d,m,t,b,c,l},第二人提交答案是:{o,m,t,l,a,g,f,d,b,c},二人分别的得分是: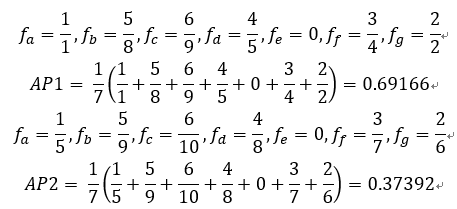
ft中分子表示t在找出的正确的新闻(红色标识)的位置,分母表示在提交集合中的位置。
计算每一条的得分进行加权平均得出总分。
处理流程:
- 数据处理
- csv文件转换为txt格式,并去除标点符号;
- 使用jieba分词将句子变为词语,并去除停用词;
2. 相似度计算方法
编辑距离+向量距离
- Levenshtein距离:从一个字符串修改到另一个字符串时,编辑单个字符(比如修改、插入、删除)所需要的最少次数;
从字符串“kitten”修改为字符串“sitting”:
因此“kitten”和“sitting”的Levenshtein距离为3。
实现:python-Levenshtein包中包含distance函数:
distance(s1,s2); - 使用doc2bow计算距离:
doc2bow:每个文档用一个向量来表示。
创建语料库:
documents = ["Human machine interface for lab abc computer applications",
"A survey of user opinion of computer system response time",
"The EPS user interface management system",
"System and human system engineering testing of EPS",
"Relation of user perceived response time to error measuremen",
"The generation of random binary unordered trees",
"The intersection graph of paths in trees",
"Graph minors IV Widths of trees and well quasi ordering",
"Graph minors A survey"]
分词,去除停用词:
[['human', 'interface', 'computer'],
['survey', 'user', 'computer', 'system', 'response', 'time'],
['eps', 'user', 'interface', 'system'],
['system', 'human', 'system', 'eps'],
['user', 'response', 'time'],
['trees'],
['graph', 'trees'],
['graph', 'minors', 'trees'],
['graph', 'minors', 'survey']]
形成字典:
gensim.corpora.dictionary.Dictionary类为每个出现在语料库中的词分配了一个整型的id,id和词形成映射,即词典:
{‘minors’: 11, ‘graph’: 10, ‘system’: 5, ‘trees’: 9, ‘eps’: 8, ‘computer’: 0,’survey’: 4, ‘user’: 7, ‘human’: 1, ‘time’: 6, ‘interface’: 2, ‘response’: 3}
用向量表示文本:
new_doc = "Human computer interaction"
new_vec = dictionary.doc2bow(new_doc.lower().split())
new_vec即[(0, 1), (1, 1)]
建立语料之后,使用两种方法计算:
1. BOW词袋模型:由doc2bow变为词袋,输出的格式为:[(0, 1), (1, 1)]
2. 建立TFIDF:使用tf-idf 模型得出语料库的tf-idf 模型
两种模型都可以使用similarities.Similarity获取测试向量和语料库中最接近的文档向量。
doc2vec计算距离:
- 基于word2vec的基础发展;
- Word2vec考虑词level上的语义信息,但是没有考虑句子的上下文信息,如果取词的向量均值表示句子的向量,会缺失单词之间的排列顺序对句子和文本之间的影响。
3. 结果
| 方法 | 分值 |
|---|---|
| doc2bow | 0.1012 |
| tf-idf | 0.0792 |
| levenshtein | 0.0610 |
后记:源代码可在此处下载